Filegroups em SQL Server
Filegroups em SQL Server são coleções nomeadas de arquivos e são usados para simplificar o posicionamento de dados.
O posicionamento de dados propiciado pelos filegroups melhoram o desempenho distribuindo dados por um ou mais discos e usando threads paralelos para processamento de consultas.
Os filegroups também facilitam a manutenção dos bancos de dados.
Um boa prática é separar as tabelas mais acessadas em filegroups diferentes localizados em controladoras e discos distintos, de modo a não haver concorrência de I/O (Input/Output), otimizando consultas e escritas no banco.
Também é possível utilizar vários filegroups para separar tabelas de seus índices no cluster, otimizando os acessos a dados.
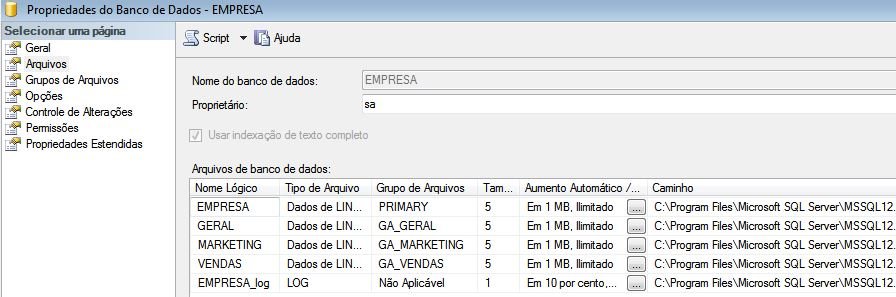
Os filegroups são úteis para separar dados com diferentes exigências de capacidade de gerenciamento, separando dados atualizados com frequencia dos dados estáticos.
Os bancos de dados podem ter filegroups principais e vários filegroups definidos pelo usuário.
O filegroup principal contém o arquivo de dados principal com as tabelas do sistema e arquivos secundários definidos pelo usuário não alocados em outros filegroups.

Arquivos de LOG são os únicos que não podem ser divididos em filegroups ou arquivos secundários. O que pode ser feito é a separação do arquivo LDF do disco em que está arquivo de dados principal para evitar a concorrência de consultas/gravações.
Conheça o curso de Segurança em Redes de Computadores e entenda os diversos tipos de ataques que existem, bem como as peças do quebra-cabeça que integram a defesa de uma rede, entre elas: Firewall, IPS, Proxy, Anti-Spam, Anti-vírus, Anti-Malware, VPN, Sandboxing, NAC, etc.

Link do curso: https://go.hotmart.com/A69498318E
Dúvidas ou sugestões? Deixem nos comentários! Para mais dicas, acesse o nosso canal no YouTube:
https://youtube.com/criandobits

